DeepLabCut Benchmark Datasets#
Note
All datasets are under a non-commerical, attribution-required license (CC BY-NC 4.0: https://creativecommons.org/licenses/by-nc/4.0/). Please contact us if you have any questions. TRI-MOUSE, PARENTING-MOUSE, MARMOSETS, and FISH are related to Lauer et al. 2022 (Nature Methods). HORSE-10, -C are related to Mathis, Biasi et al. 2021 (WACV).
|
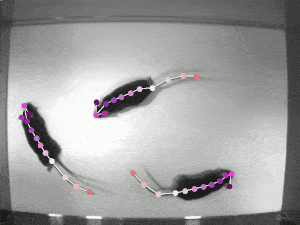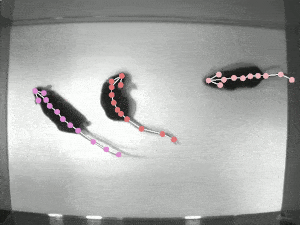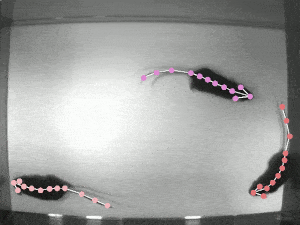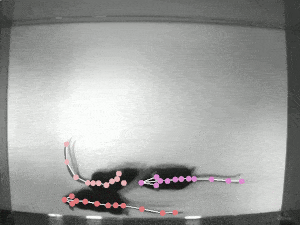
TRI-MOUSE [train | test ]: Three wild-type (C57BL/6J) male mice ran on a paper spool following odor trails (Mathis et al 2018). These experiments were carried out in the laboratory of Venkatesh N. Murthy at Harvard University. Data were recorded at 30 Hz with 640 x 480 pixels resolution acquired with a Point Grey Firefly FMVU-03MTM-CS. One human annotator was instructed to localize the 12 keypoints (snout, left ear, right ear, shoulder, four spine points, tail base and three tail points). All surgical and experimental procedures for mice were in accordance with the National Institutes of Health Guide for the Care and Use of Laboratory Animals and approved by the Harvard Institutional Animal Care and Use Committee. 161 frames were labeled, making this a real-world sized laboratory dataset. |
|
PARENTING-MOUSE: [train | test ]: Parenting behavior is a pup directed behavior observed in adult mice involving complex motor actions directed towards the benefit of the offspring. These experiments were carried out in the laboratory of Catherine Dulac at Harvard University. The behavioral assay was performed in the homecage of singly housed adult female mice in dark/red light conditions. For these videos, the adult mice was monitored for several minutes in the cage followed by the introduction of pup (4 days old) in one corner of the cage. The behavior of the adult and pup was monitored for a duration of 15 minutes. Video was recorded at 30Hz using a Microsoft LifeCam camera (Part#: 6CH-00001) with a resolution of 1280 x 720 pixels or a Geovision camera (model no.: GV-BX4700-3V) also acquired at 30 frames per second at a resolution of 704 x 480 pixels. A human annotator labeled on the adult animal the same 12 body points as in the tri-mouse dataset, and five body points on the pup along its spine. Initially only the two ends were labeled, and intermediate points were added by interpolation and their positions was manually adjusted if necessary. All surgical and experimental procedures for mice were in accordance with the National Institutes of Health Guide for the Care and Use of Laboratory Animals and approved by the Harvard Institutional Animal Care and Use Committee. 542 frames were labeled, making this a real-world sized laboratory dataset. |
|
MARMOSETS [train | test ]: All animal procedures are overseen by veterinary staff of the MIT and Broad Institute Department of Comparative Medicine, in compliance with the NIH guide for the care and use of laboratory animals and approved by the MIT and Broad Institute animal care and use committees. Video of common marmosets (Callithrix jacchus) was collected in the laboratory of Guoping Feng at MIT. Marmosets were recorded using Kinect V2 cameras (Microsoft) with a resolution of 1080p and frame rate of 30 Hz. After acquisition, images to be used for training the network were manually cropped to 1000 x 1000 pixels or smaller. The dataset is 7,600 labeled frames from 40 different marmosets collected from 3 different colonies (in different facilities). Each cage contains a pair of marmosets, where one marmoset had light blue dye applied to its tufts. One human annotator labeled the 15 marker points on each animal present in the frame (frames contained either 1 or 2 animals). |
|
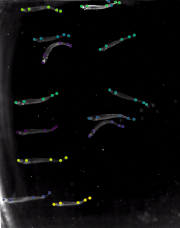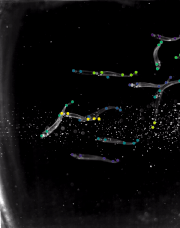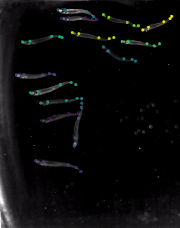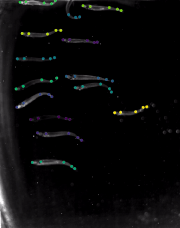
FISH [train | test ]: Schools of inland silversides (Menidia beryllina, n=14 individuals per school) were recorded in the Lauder Lab at Harvard University while swimming at 15 speeds (0.5 to 8 BL/s, body length, at 0.5 BL/s intervals) in a flow tank with a total working section of 28 x 28 x 40 cm as described in previous work, at a constant temperature (18±1°C) and salinity (33 ppt), at a Reynolds number of approximately 10,000 (based on BL). Dorsal views of steady swimming across these speeds were recorded by high-speed video cameras (FASTCAM Mini AX50, Photron USA, San Diego, CA, USA) at 60-125 frames per second (feeding videos at 60 fps, swimming alone 125 fps). The dorsal view was recorded above the swim tunnel and a floating Plexiglas panel at the water surface prevented surface ripples from interfering with dorsal view videos. Five keypoints were labeled (tip, gill, peduncle, dorsal fin tip, caudal tip). 100 frames were labeled, making this a real-world sized laboratory dataset. |
|
HORSE-10Task: typical human pose estimation benchmarks, such as MPII pose and COCO, contain many different individuals (>10K) in different contexts, but only very few example postures per individual. In real world application of pose estimation, users want to estimate the location of user-defined bodyparts by only labeling a few hundred frames on a small subset of individuals, yet want this to generalize to new individuals. Thus, one naturally asks the following question: Assume you have trained an algorithm that performs with high accuracy on a given (individual) animal for the whole repertoire of movement - how well will it generalize to different individuals that have slightly or a dramatically different appearance? Unlike in common human pose estimation benchmarks here the setting is that datasets have many (annotated) poses per individual (>200) but only few individuals (1-25). To allow the field to tackle this challenge, we developed this benchmark, called Horse-10, comprising 30 diverse Thoroughbred horses, for which 22 body parts were labeled by an expert in 8,114 frames (collectively, this data is called Horse-30). Horses have various coat colors and the “in-the-wild” aspect of the collected data at various Thoroughbred yearling sales and farms added additional complexity. You should train only on one split at a time - please read the full details here: http://horse10.deeplabcut.org. |
|
HORSE-C: Horse-C is derived from Horse-30, and applied the ImageNet-C style corruptions. In Mathis*, Biasi* et al, 2021 WACV we contrast the inherent domain shift in out-of-domain individual ID to common corruptions (and here too show a boost with ImageNet pretrianing). Horse-C is comprised of 75 evaluation settings with 8,114 images each, yielding a total of 608,550 images. Please read the full details here: http://horse10.deeplabcut.org. |
)